PDFソフトといえばAbobeのAcrobatです。
だって、PDFはAdobeが開発したのですから。ふりかえると現在のDCの前に6.7.8.9の各バージョンを購入していました。丁寧にシリアル番号を控えている。ver9のCDが6枚もある(当時はスタッフが多かった)。9より前のCDは行方不明(9を大量購入したので無用と判断し廃棄したのだろう。とっておけばよかった)。9より後のパッケージを購入していない理由は9が使い勝手がよく現役だからです。
現在のDCはパッケージで売ってくれません。買い切りでなくザブリスクです。人数分いるので司法書士専用ソフトに匹敵する費用が毎月かかるが、Adobeの儲けの態度ではないのだろう。DCというよりPDFというソフトウエアはインフラそのものというところがあり、常に進化を求められているのだと想像します。 電子署名というインフラに密着している司法書士事務所としては、最新の電子署名技術に触れて熟知していなければならないところもある気がする。
買い切りを求める人は、ランニングコストだけを問題にしているのではないと思う。アップグレードを積極的に拒んでいるのだ。PDFファイル化ができればそれでよく、余計な機能はまつたく邪魔なのです。Acrobat6ぐらいがちょうどいい。軽くて速いのがいい。電子署名なんかしたくない。ところで、DCとそれ以前のバ―ジョンは共存できない(二つをインストールできない)。そこで、日常PDF業のために、干渉しないAdobe以外のPDFソフトも導入するはめになってしまった。
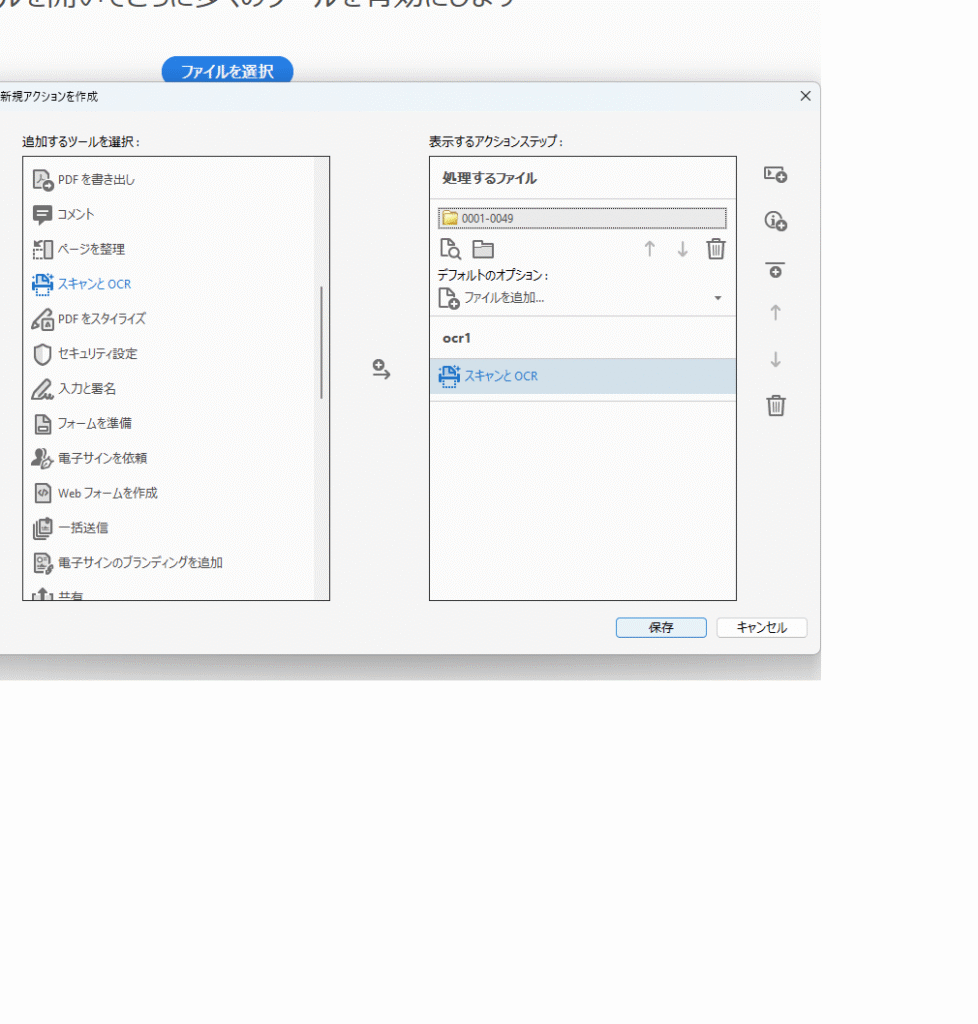
使いづらいがDCの機能はすごい。この正月の3日間わが事務所のDCくんは、千冊ほどの解本をアクションウイザ―ド自動化によって休むことなくOCR化してくれた。 こんな芸当はJustさんやエレメントくんではできそうにない。
アクションウイザ一ドを組むのにはかなり苦労しました。条件付設定を仕込むだけでプログラムは不要でした。しかし6時間も作業したところでフリーズしてしまう。マシンが弱いのだろう。事務所PCはどれもSSDに換装済でメモリを32MBに上げてあるのに。途中で止めることはできず正月そうそう最新PCを大須商店街で買ってきて成功しました。35万円もした。高校生のころからIBMだったのでそのあたりで統一していたのですがツクモの自作PCという例外が生まれてしまった。
CPUの性能差とビデオカードの影響とみた。こういうのを目の当たりにすると、全体的な買い替えなのかなあと頭によぎり、まだ捨てきれていない旧代PCの山をみて思いとどまります。ゲームをやるわけでもなくCADを扱うのでもない。ただワープロだけ。だからSSDと最強メモリの先は無用と思っていた。これからは、AI処理スペックのためにそうはいかなくなるのだろう。この千冊処理はRAGの前処理です。
ところで、DCが高価だから全PCにインストールしてしないというわけではない。 使い勝手が悪いからだ。前述したが機能が多すぎる。機能の多さが重くしている。あっても困るものではないが使わない機能ならむしろないほうがいいと思うようになった。こうよぎるのは、9があるからで、DCしかないのならそんな気持ちにならないのだろう。
回転木馬のデットヒート