sites/21055287
1 Daily notes
2 Link
3 Metadata(Properties)
4 Folder
5 Title(ノートタイトル)
DiMFiTはいわば、雑然とした情報を管理するためのフィルターです。そしてこれに「Search(検索)」を加えると、必要なメモにたどり着くための「手がかり」となります。 情報はDiMFiTというフィルターを通すことによって、ある程度分類・整理された状態で保存され、手がかりによって取り出される。メモの山からメモそのものではなく、手がかりをつまんで引っ張り上げるイメージが近いかもしれません。
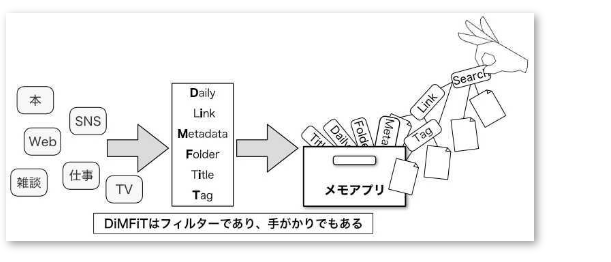
・・・そうではないのです。リンクのみに頼った整理では、必ず後でしっぺ返しを食らいます。Obsidianは整理不要のアプリではなく、日々増え続ける情報をゆるく分類するためのフィルターの種類・・・適切なルールに従って保存された情報ならば、その数がいくら増えようとも、検索やリンク、またはその他の手がかりによって適切にフィルタリングされ、ノイズの少ない状態で取り出せるはず・・・